
Reimplementation of InfoGAN
Date:
InfoGAN is almost similar to GAN except for the fact that it is also able to learn disentangled(interpretable) representations in a completely unsupervised manner. These interpretable features can be used by many downstream tasks such as classification, regression, visualization, and policy learning in reinforcement learning. The code in this repository was reimplemented on top the official repository of the paper - InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets.
The experiments from this work are summarized in the following poster.
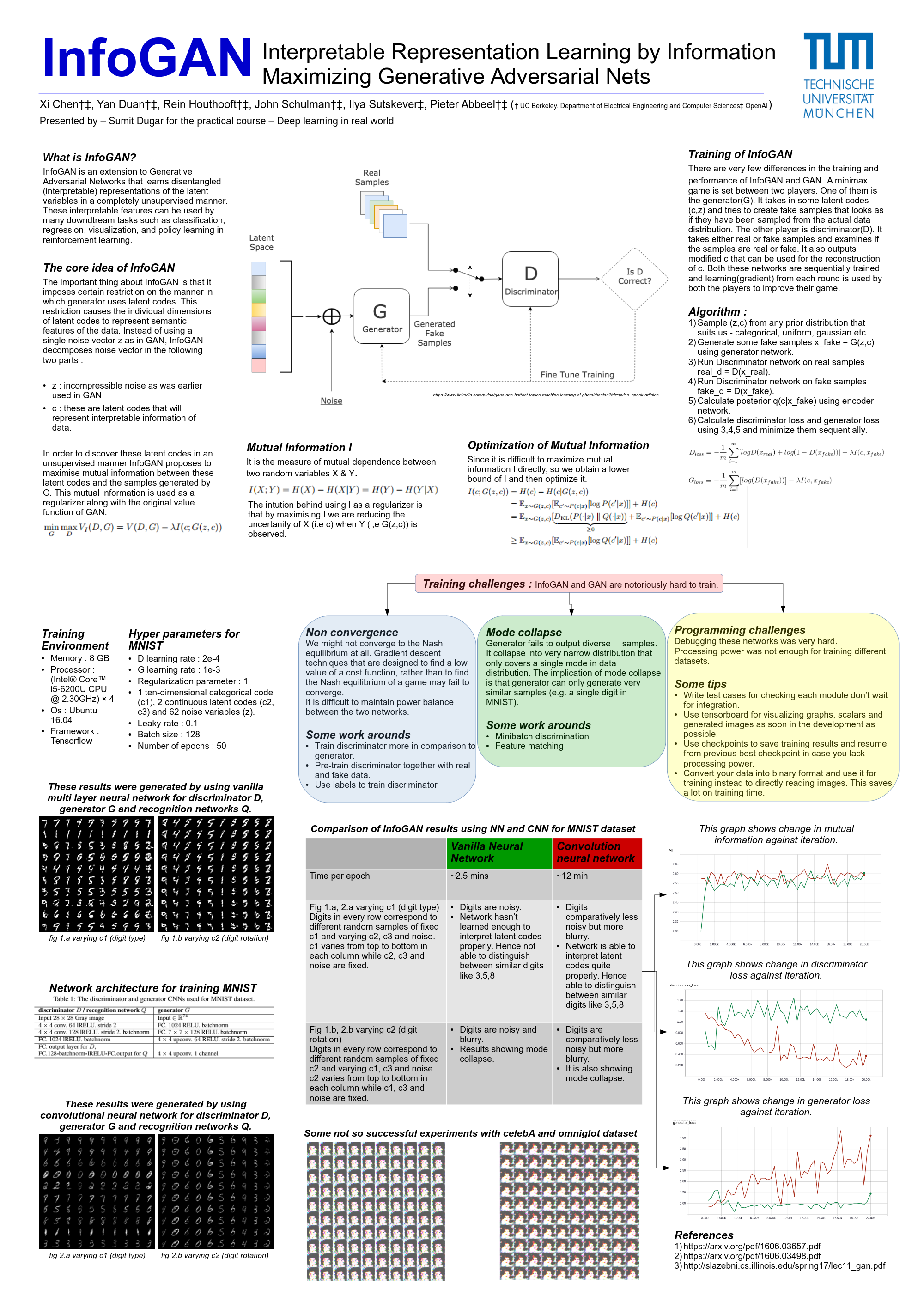
Before we learn about InfoGAN let’s review what are GANs
Generative adversarial networks(GAN) are an example of generative models. A generative model is any model that takes a training set, consisting of samples drawn from a distribution pdata and learns to represent an estimate of that distribution somehow. The result is a probability distribution pmodel. In some cases, the model estimates pmodel explicitly, and in other cases, the model is only able to generate samples from pmodel, some models are able to do both. GANs focus primarily on sample generation.
 [1]
[1]
The basic idea of GANs is to set a minimax game between two players. One of them is the generator(G). It takes in some latent codes (noise z) and tries to create fake samples that looks as if they have been sampled from the actual data distribution. The other player is discriminator(D). It takes either real or fake samples(with equal probability) and examines if the samples are real or fake. The learning(gradient) from each round is used by both the players to improve their game. This ideally goes on till D is not able to discriminate between real and fake samples.
Formally, the minimax game is given by the following value equation :
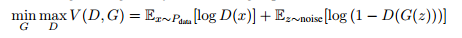 [2]
[2]
Why you should learn about InfoGAN?
InfoGAN is almost similar to GAN except for the fact that it is also able to learn disentangled(interpretable) representations in a completely unsupervised manner. These interpretable features can be used by many downdtream tasks such as classification, regression, visualization, and policy learning in reinforcement learning.
Core idea of InfoGAN
The important thing about InfoGAN is that it imposes certain restriction on the manner in which generator uses latent codes. This restriction causes the individual dimensions of latent codes to represent semantic features of the data. Instead of using a single noise vector z as in GAN, InfoGAN decomposes noise vector in the following two parts :
- z : incompressible noise as was earlier used in GAN
- c : these are latent codes that will represent interpretable information of data.
In order to discover these latent codes in an unsupervised manner InfoGAN proposes to maximise mutual information between these latent codes and the samples generated by G. This mutual information is used as a regularizer along with the original value function of GAN. Formallly, the value function now looks tike this :
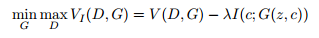 [3]
[3]
Mutual Information I : It is the measure of mutual dependence between two random variables X & Y.
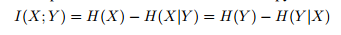 [4]
[4]
The intution behind using I as a regularizer is that by maximising I we are reducing the uncertanity of X (i.e c) when Y (i,e G(z,c)) is observed.
Since it is difficult to maximize mutual information I directly, so we obtain a lower bound of I and then optimize it. Formally it looks like this :
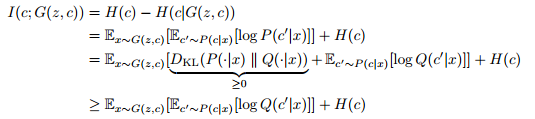 [5]
[5]
How InfoGAN actually works
There are very few differences in the working and performance of InfoGAN and GAN. Generator uses both z & c to create fake samples(x = G(z,c)). Latent codes c can be sampled from any distribution that suits us - categorical, uniform, gaussian etc. The discriminator not only outputs prediction whether sample is real or fake but it also outputs modified c that can be used for the reconstruction of c. We use the same discriminator basicly and only change the output layer for the above mentioned two outputs.
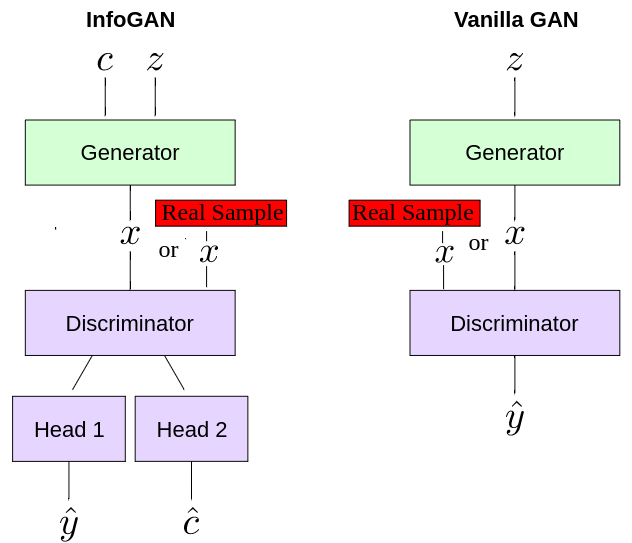 [6]
[6]
Experiments
InfoGAN successfully disentangles writing styles from digit shapes on the MNIST dataset, pose from lighting of 3D rendered images, and it also discovers visual concepts that include hair styles, presence/absence of eyeglasses, and emotions on the CelebA face dataset. Interpretable representations that are learned by InfoGAN are competitive with representations learned by existing supervised methods.
 [7]
[7]
For the mnist dataset three latent codes were choosen. c1 a discontinuous categorical code that captures drastic shape changes. c2 & c3 are continuous codes that captures rotation and width of digits respectively. Consider the following information while analysing the results from the above images e.g in (a) :
- Only one of the latent code c1 is varied and other latent codes (c2,c3) and noise z are kept constant in each row of (a).
- A column contains five samples for a fixed c1 and varied c2, c3 and noise.
Conclusion
InfoGAN is unsupervised and learns interpretable and disentangled representations. In addition, InfoGAN adds only negligible computation cost on top of GAN. The core idea of using mutual information to induce representation can be applied to other methods like VAE, which could be a promising area of future work.
References
- https://arxiv.org/abs/1606.03657
- https://arxiv.org/abs/1701.00160
- https://www.linkedin.com/pulse/gans-one-hottest-topics-machine-learning-al-gharakhanian?trk=pulse_spock-articles
- https://danieltakeshi.github.io/2017/03/05/understanding-generative-adversarial-networks/
- http://aiden.nibali.org/blog/2016-12-01-implementing-infogan/
- https://blog.openai.com/generative-models/